
S3のデータをRedshiftに自動連携(Glue+クエリスケジュール)
事業開発Gに所属しているaishimaです。
普段は、Tableau・Treasure Data・AWSを使用してデータ分析周りの仕事をしてます。
AWSのサービスでS3内のデータをクエリして分析を行いたい場合、AthenaやRedshiftが候補に上がるかと思います。
どちらもサーバレスでインフラを別途維持する必要もなくそれほど初期構築の必要がなく分析を始めることができます。Athenaは特にS3に保存されているデータを直接問い合わせることができ、現状AWS内にデータ分析基盤を持ってなく、検証用として一時的にクエリを実行して内容を確認したりする場合にはAthenaを採用するほうがコスパがいいことが多いかと思います。
一方で、例えば、既にRedshiftを導入している場合や、大規模かつ複雑なクエリが必要、実行時に高速なクエリ結果の出力が求められるケースではRedshiftを採用することが多いかと思います。
今回紹介するのは、S3のデータをRedshiftに連携するケースに関するものになります。少し、実務に合わせたケースとして以下を自動連携したいといったものを想定しました。
- データはS3内の同一のフォルダに毎日同時刻に格納される
- S3内のデータは前日の24時間分の履歴(前日の購買データやWebアクセスログのようなものを想定)
- Redshiftには累計データを保管したい、またS3のデータをそのまま格納ではなくある程度整形して保存したい
AWSに明るい方なら、この時点でいくつも方法を考えつくかと思いますが、自分は今回 Glue と Redshift のスケジュール実行を利用した方法を紹介しようと思います。
(GlueはAWSが提供しているサーバレスのETLツールです。S3等のデータストアからので抽出や正規化、データ連携の処理を簡単に実現できる機能です)
目次
GlueによるS3→Redshiftへのデータ連携
S3にデータを準備
まず、S3内に 毎日同時刻に格納されるフォルダとその中に転送するファイルを準備します。
例えば以下のようにします。
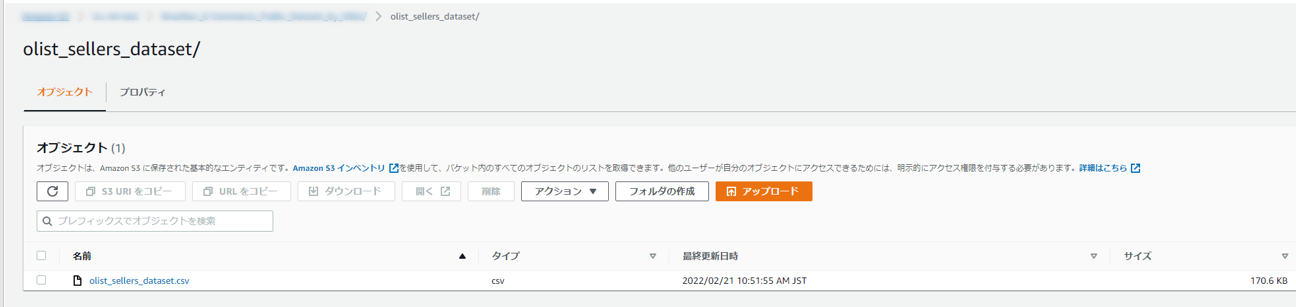
S3での準備は以上になります。
Glue による S3 データへのクローラ実行
次に、Glueの設定に入ります。まずはS3のデータを読み込みます。
クローラの設定画面に入ります。
このクローラを使用することで先程準備したS3のデータをデータカタログに格納することができます。

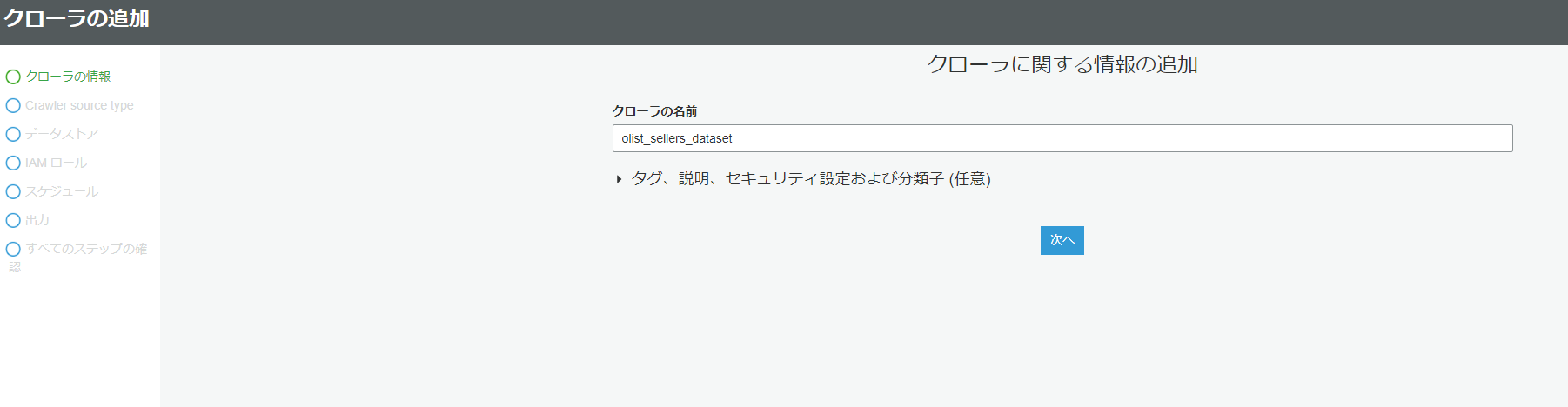
クローラの追加をクリックします。
次に、クローラの名前を追加します(こちらは任意で大丈夫です。今回はファイル名と同じにしました)
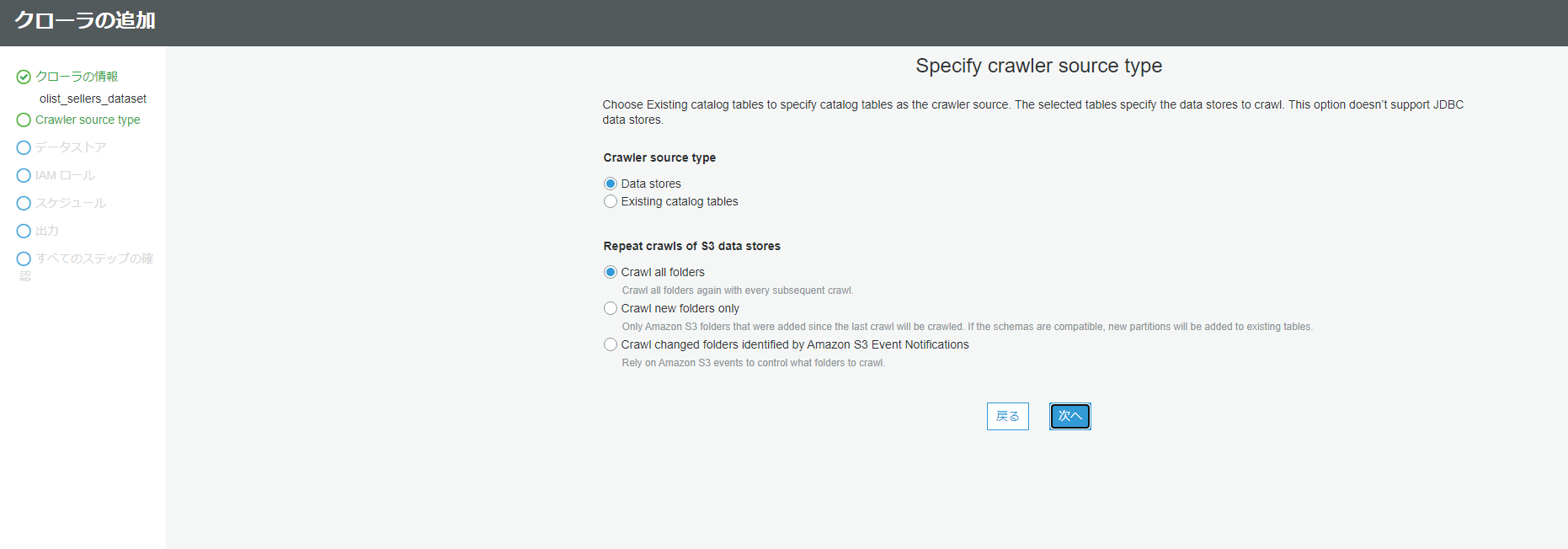
データソースの条件を選択できますが、今回はデフォルトのままで大丈夫です。
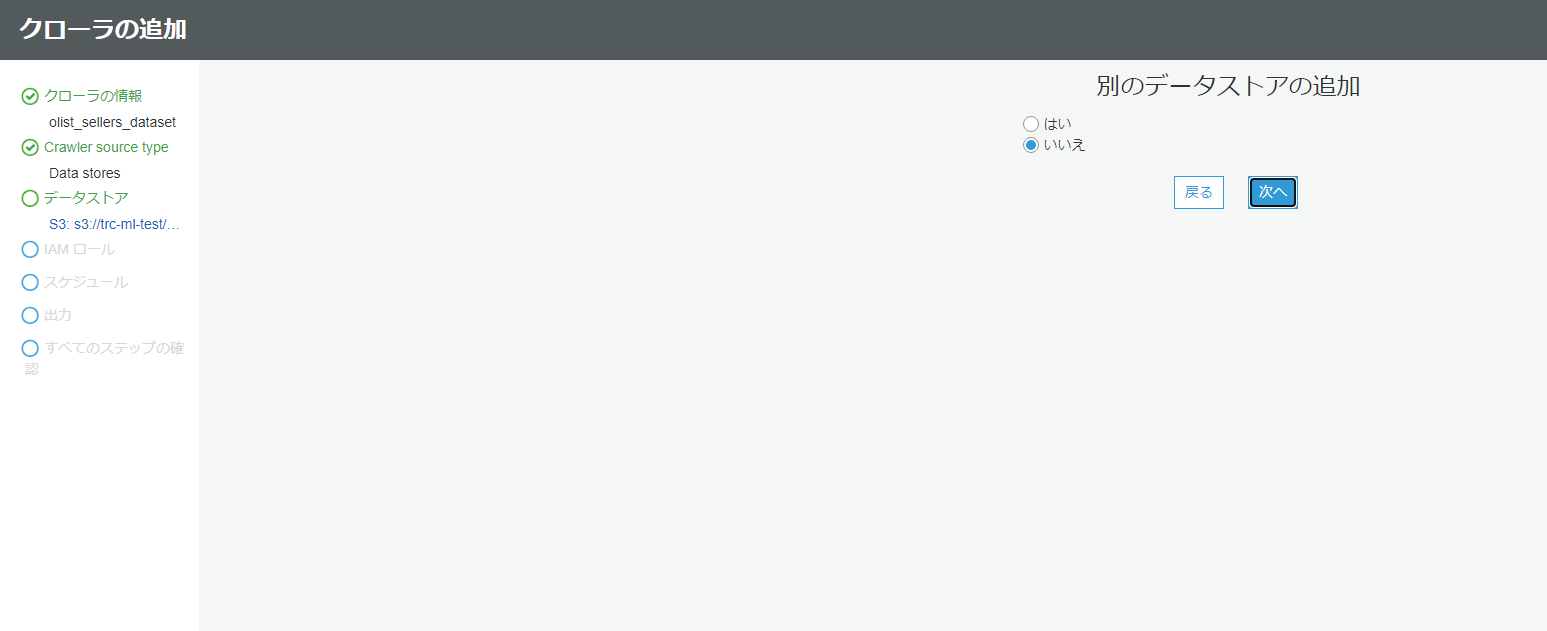
データストアの追加では、インクルードパスの箇所で先程データを格納したフォルダを指定します。

別のデータストアの追加ではいいえのままで大丈夫です。
IAMロールの設定では、既に作成済みでない場合でも、このタイミングで作成し、付与することができます。
今回は新規作成で設定します。
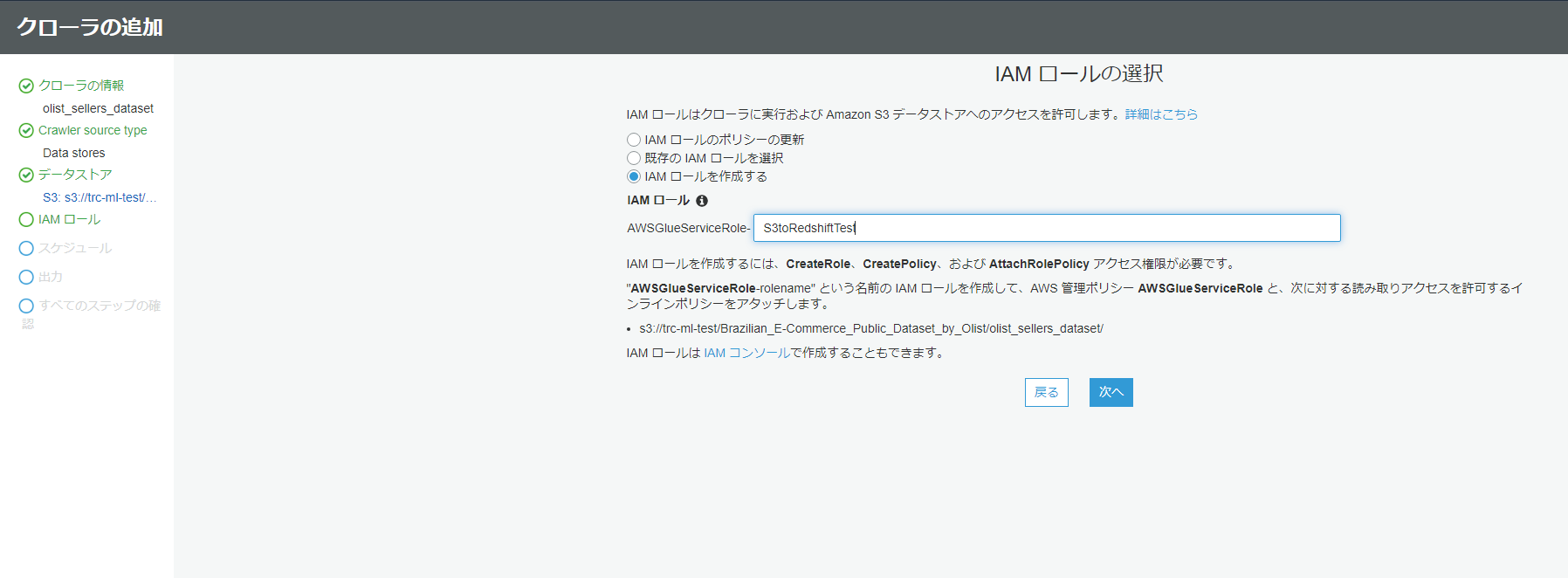
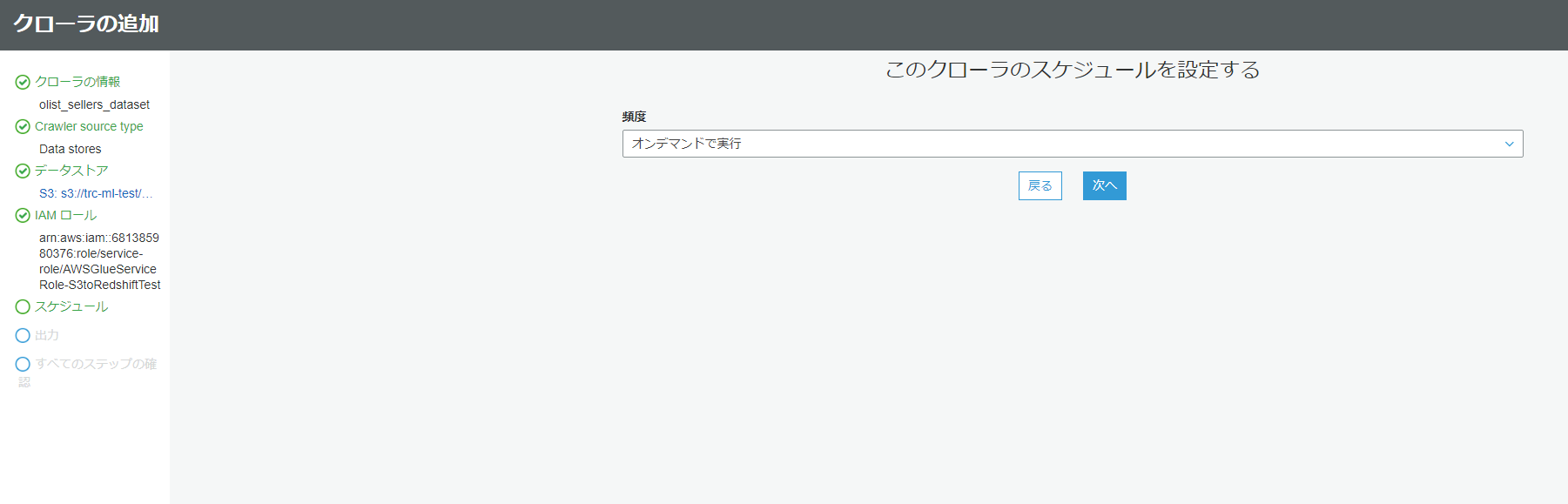
スケジュールの設定に関しては、今回は別の場所で設定するのでオンデマンドのままにしておきます。
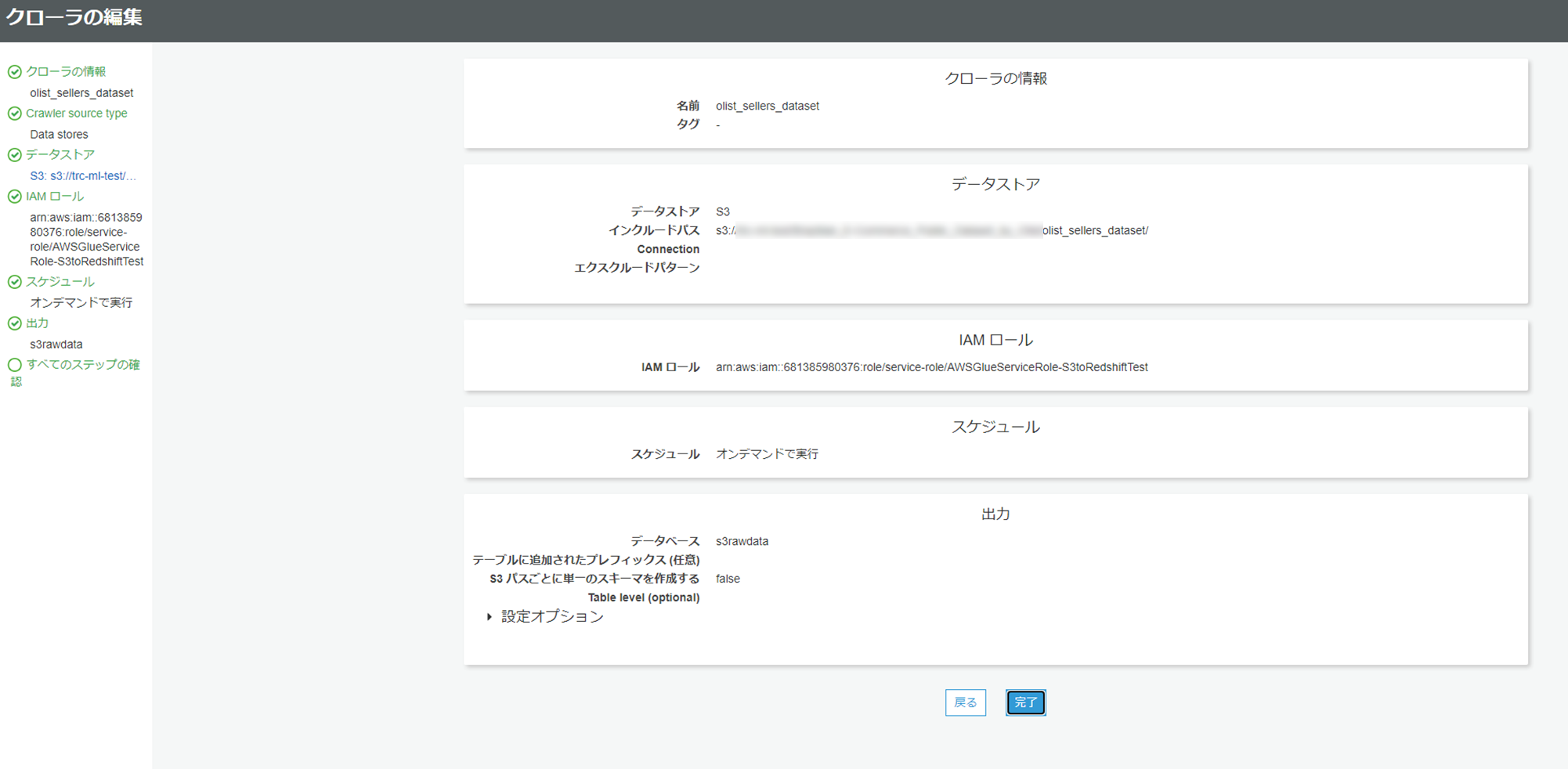
出力先のデータベース等を指定します。まだ、データベースを作成していなくても、このタイミングで作成ができます。必要であればプレフィックス等も設定しますが、今回はこのままで行きます。

これで、すべての設定が終わりました。完了ボタンを押します。

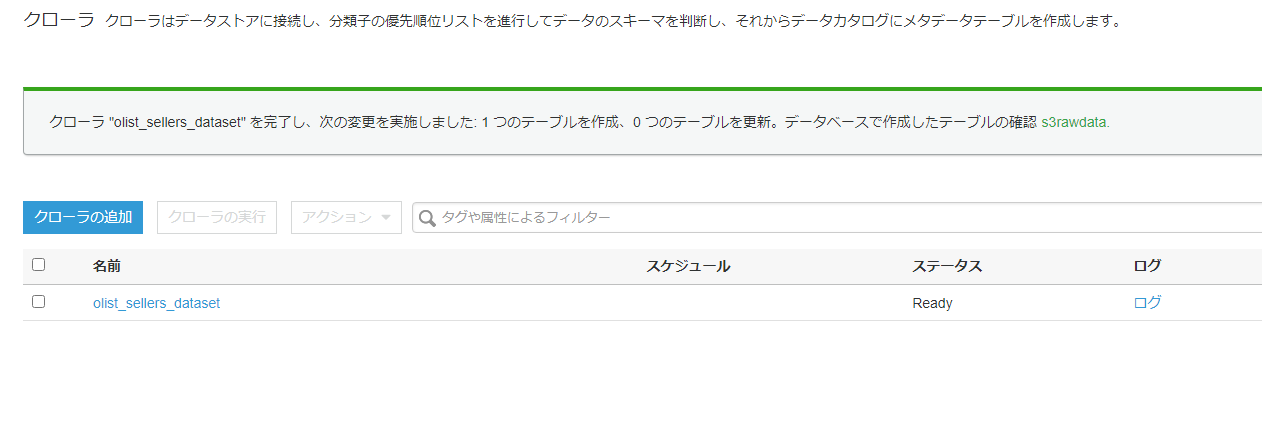
緑色のデータベース名をクリックし、テーブルを選択すると中身の詳細が確認できます。

Redshift 側でのテーブル準備
ここで、ひとまず、Glueを離れ、Redshiftの画面に移動します。
(Redshiftの初期構築に関しては割愛します。既に基盤がある設定で話を進めます)
Glue から Redshift への接続
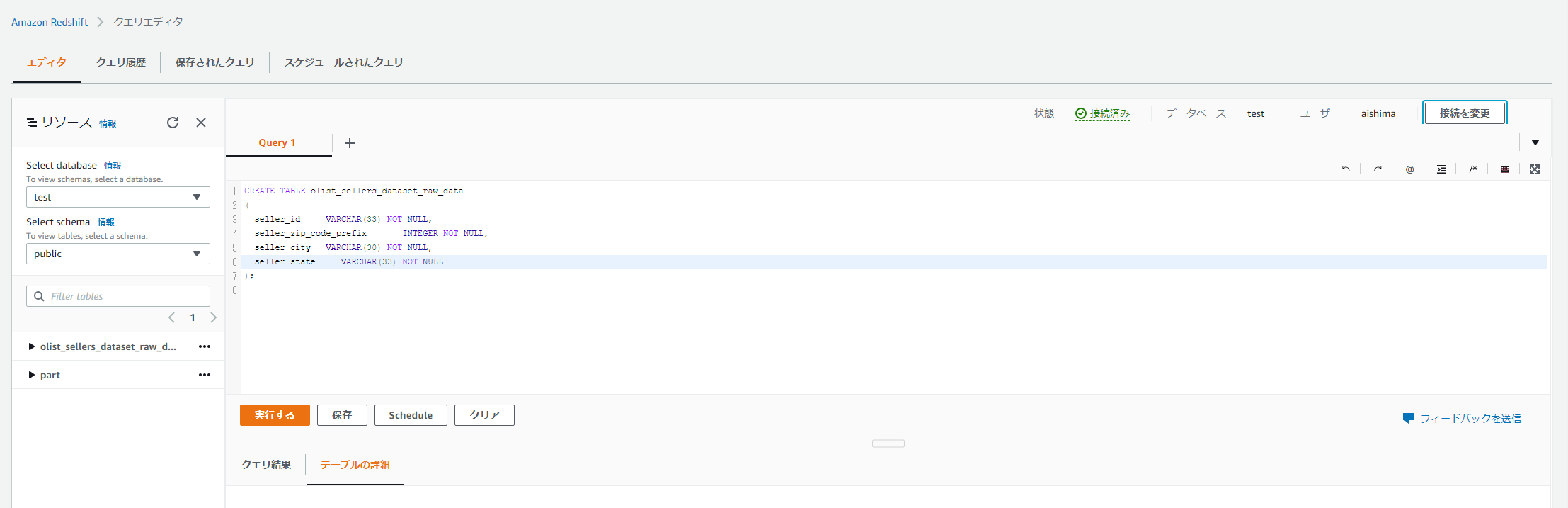
Redshift内のテーブルにGlueで作成したテーブルと同じカラムのテーブルを作成します。
(実行するとテーブルが作成されます)
再び、Glueの画面に移動します。
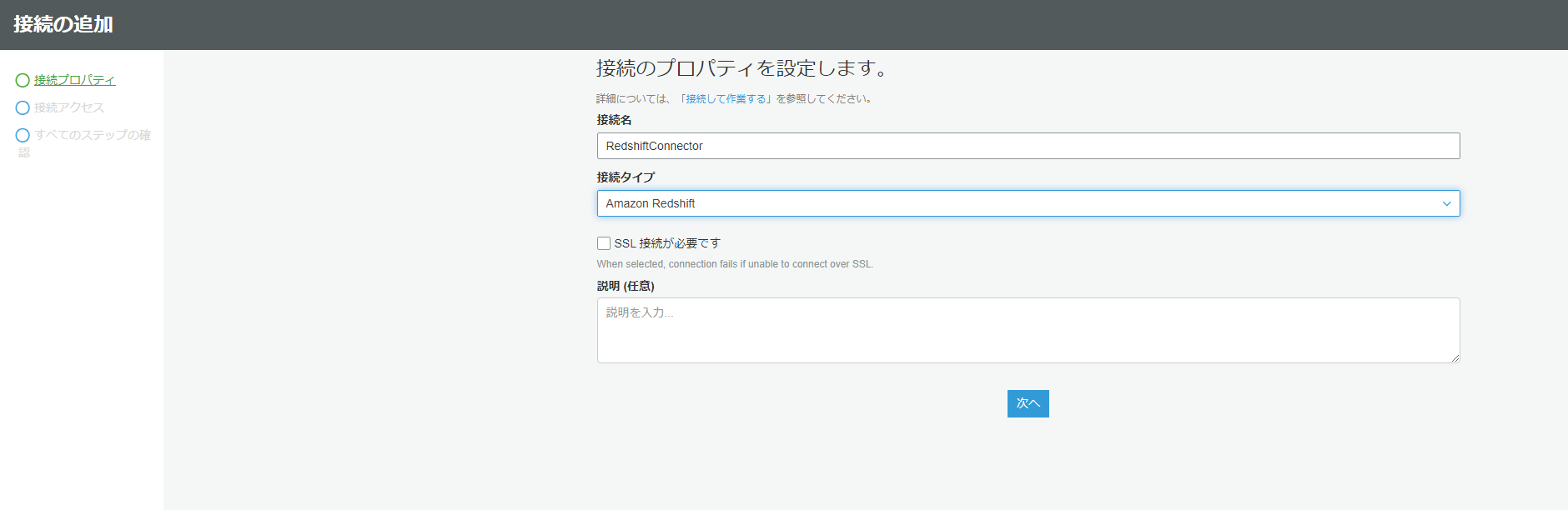
今度はRedshiftとの接続を設定します。画面左の「接続」をクリックし、接続の追加を選択します。
名前は任意で、接続先をRedshiftを選択します。
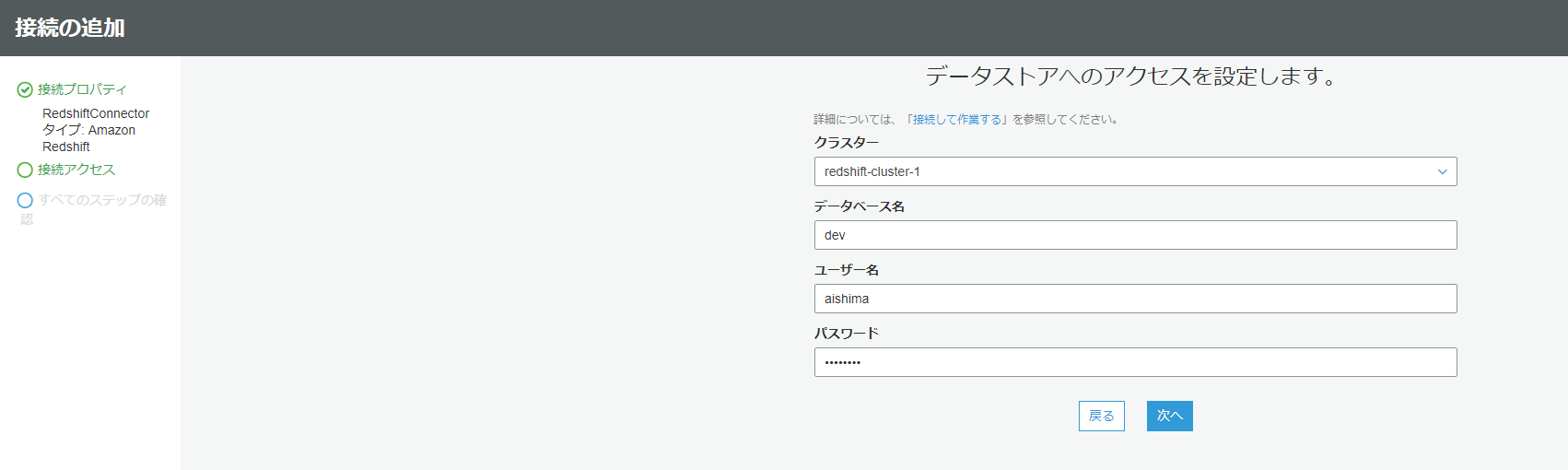
確認画面に移るので、完了ボタンを押します。完了ボタンを押すと、最初の画面に戻るので、
接続テストを行います。うまく行けば下のような画面になります。

Glue から Redshift へのクローラ実行
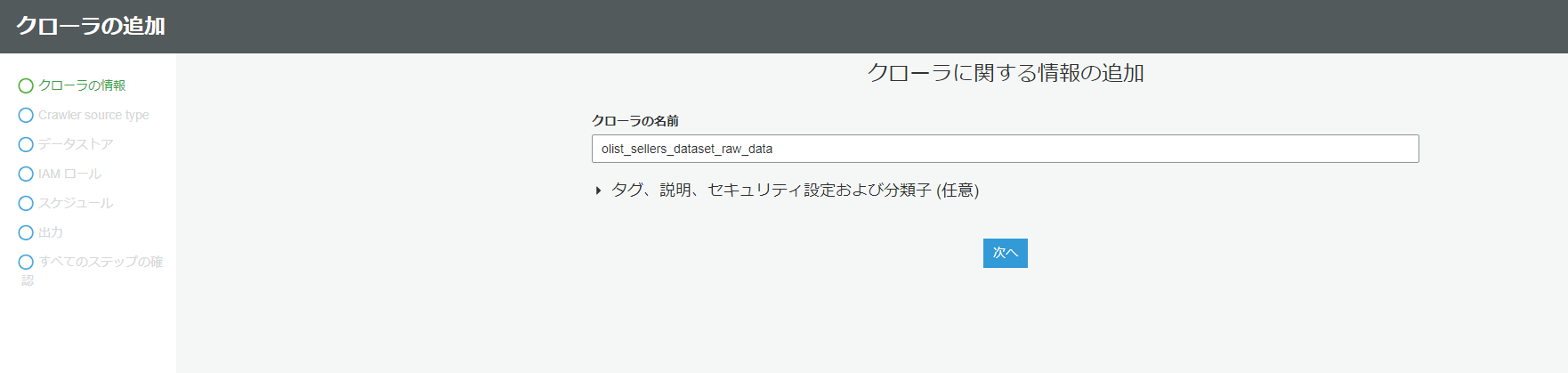
次に、再度クローラの設定画面に入ります。今度はRedshiftのテーブルを読み込みます。
クローラの追加を選択します。名称は任意で設定します。(今回はRedshift内のテーブル名と同じにしました)
インクルードパスも、空データを作成したパスを指定します。

ロールの設定では、S3のクローラ設定時に作成したものを選択します。

出力先は、S3時に作成したものとは別のデータベースで作成します。
(必須ではないですがデータが増えてくると、この設計のほうが探しやすくなると思います)
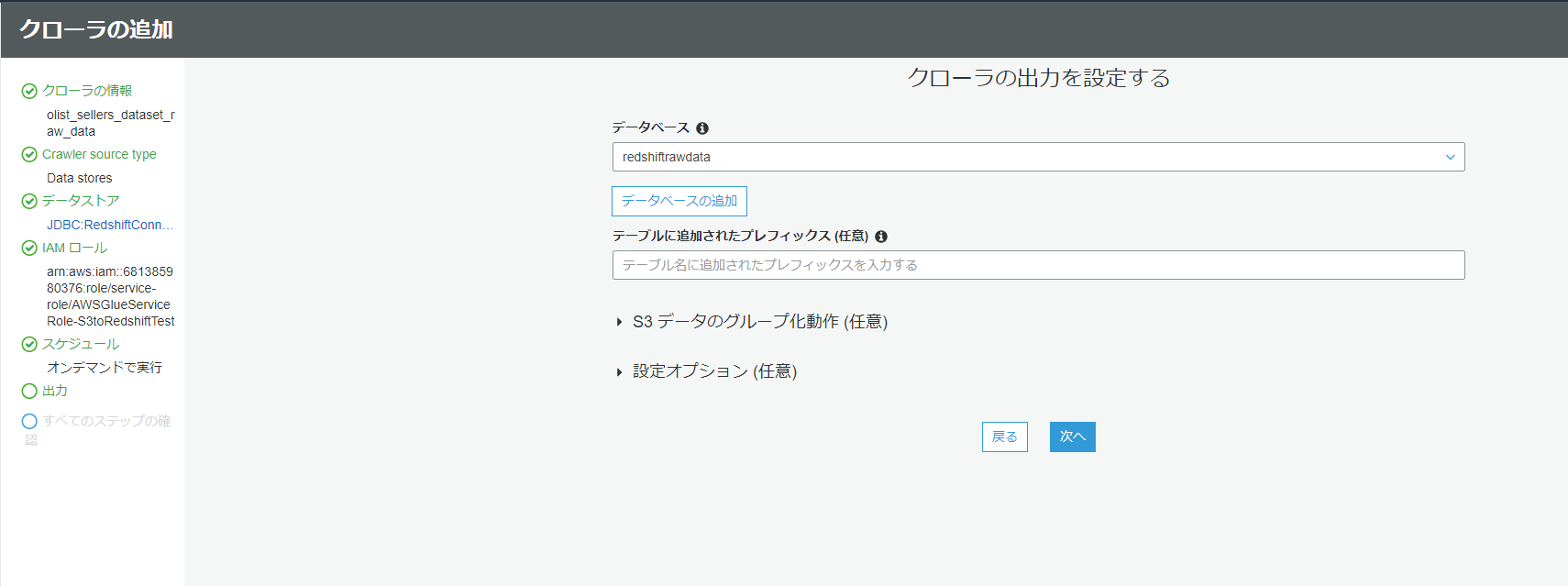
最初の画面に戻るので、同じように実行します。(成功すれば連携の準備が一通り終わりです!)
Glue ジョブ実行
長くなりましたが、、データ連携の準備ができましたので今度はGlueの左画面のジョブを選択します。
今回はlegacyモードを選択します。ジョブの追加を選択します。
ジョブプロパティの設定では名前とロールを設定します。

データソースの選択ではS3のデータを選択します。

変換タイプはそのままにしておきます。
データターゲットではRedshiftのデータを選択します。
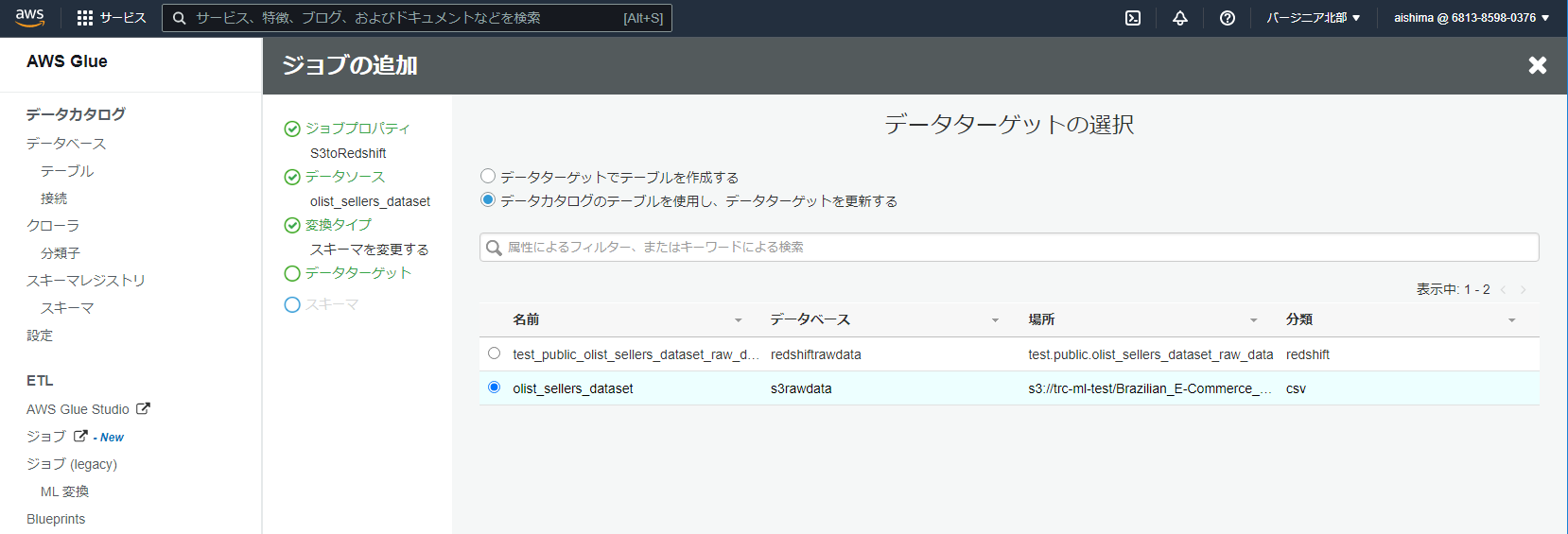
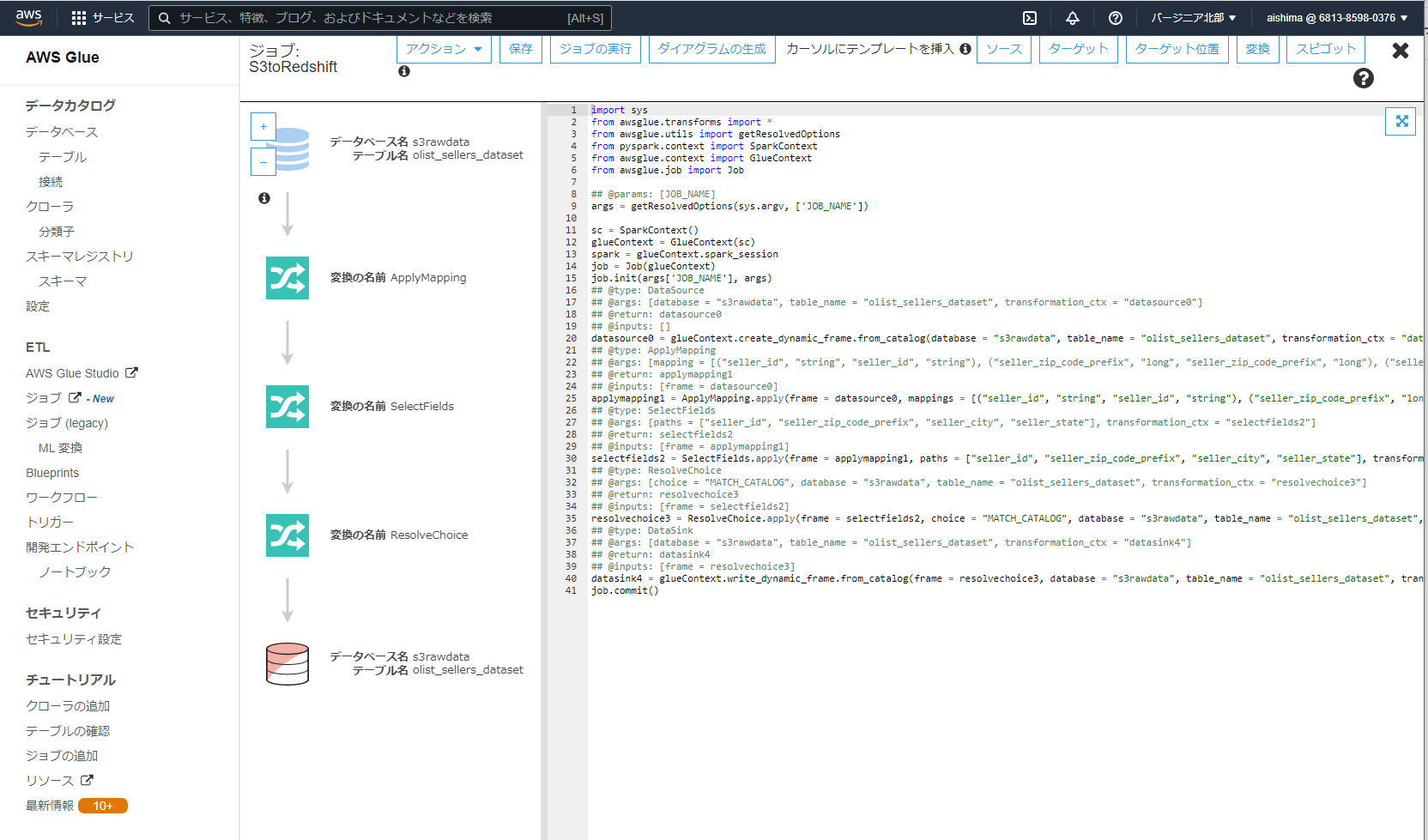
次の画面でマッピングがされます。意図した形でマッピングされてるのが確認できたら、ジョブを保存してスクリプトを編集するを選択します。

保存してジョブの実行をします。
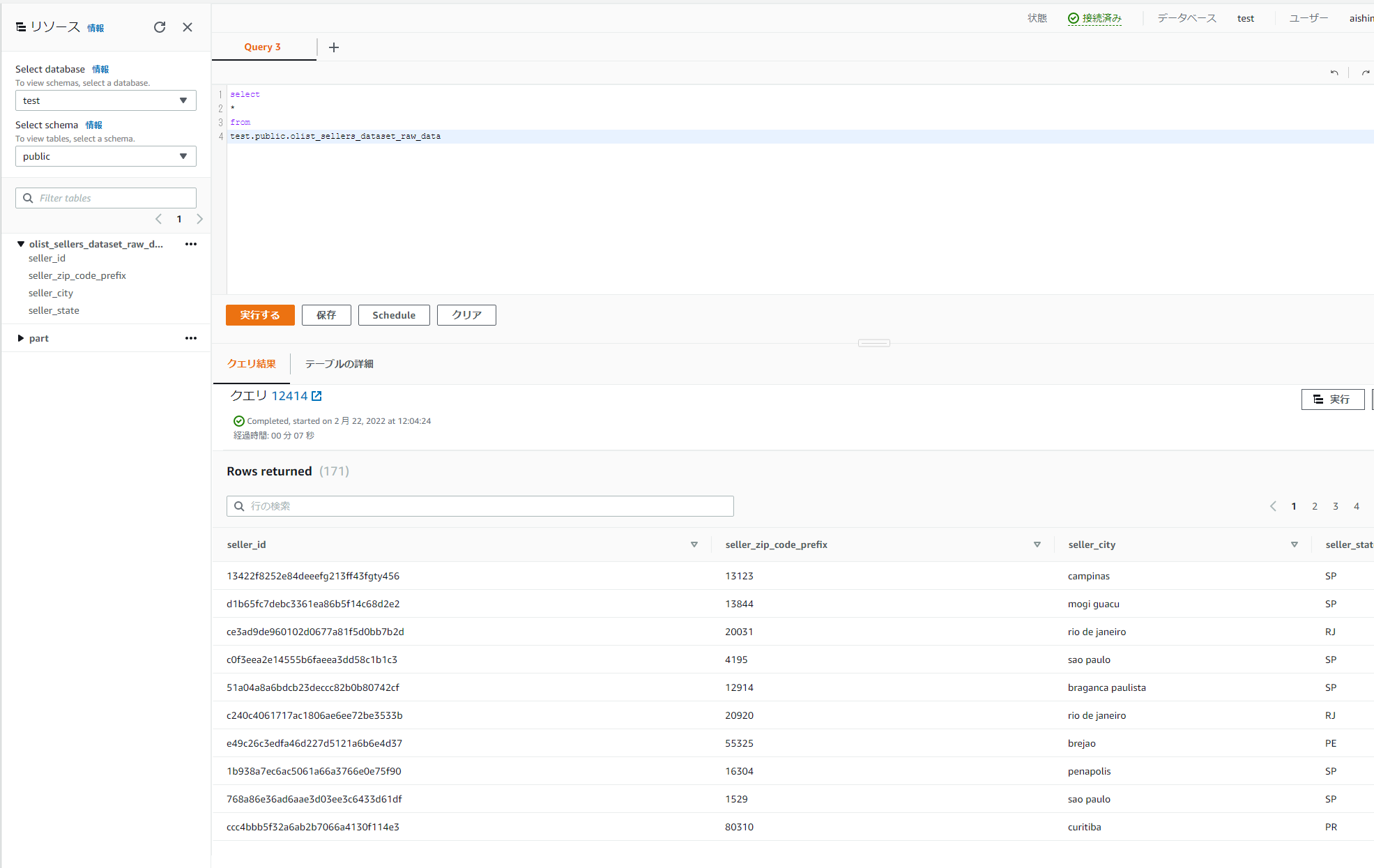
Redshiftに戻り、作成したテーブルを確認します。データが入ってきていれば成功です。
Glue トリガー設定 (定期実行設定)
後は、このままだと一回手動実行して終わりなので、スケジュール実行される設定をします。この設定はトリガーで行います。Glueの左画面のトリガーを選択し、トリガーを追加をクリックします。
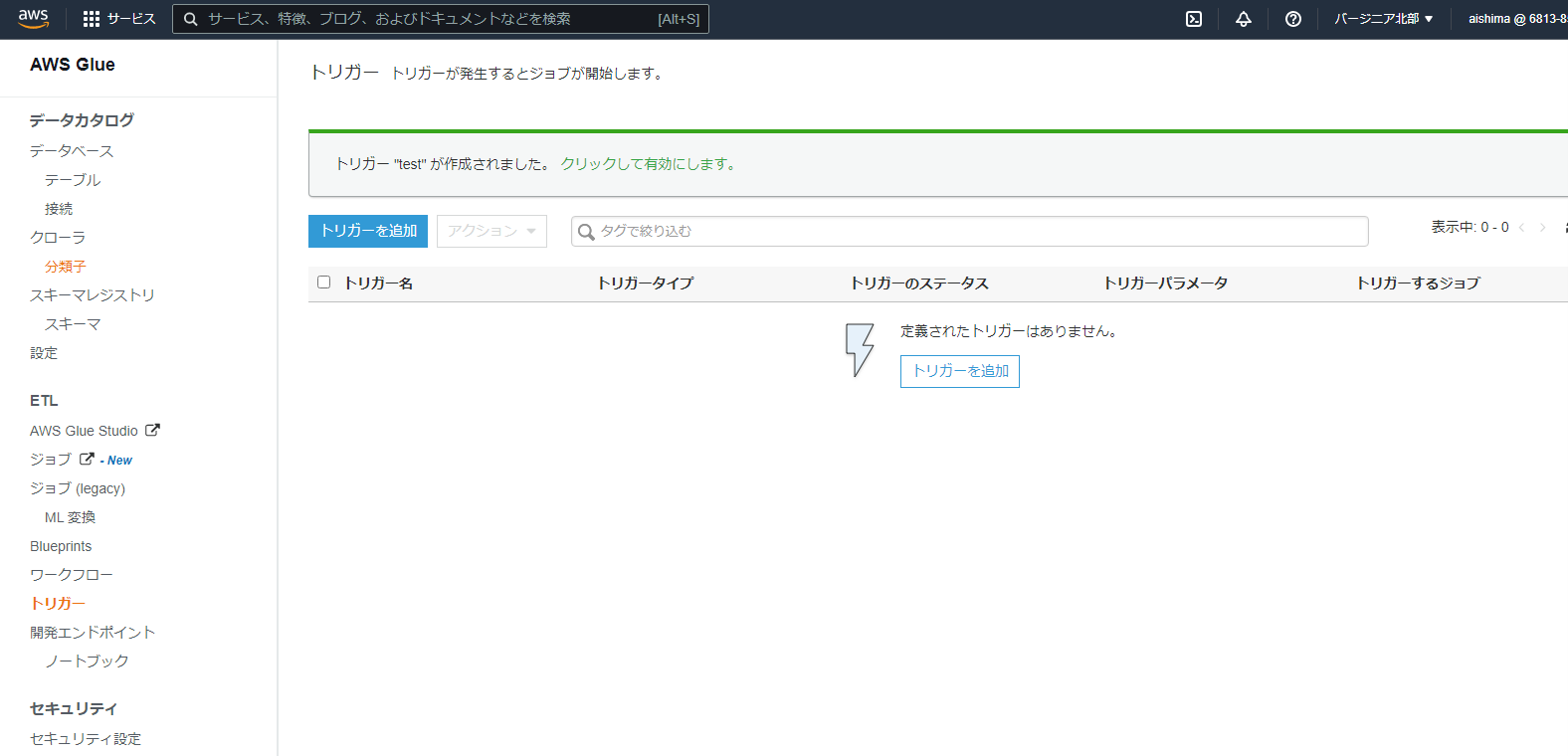
任意の時刻と頻度を設定します。
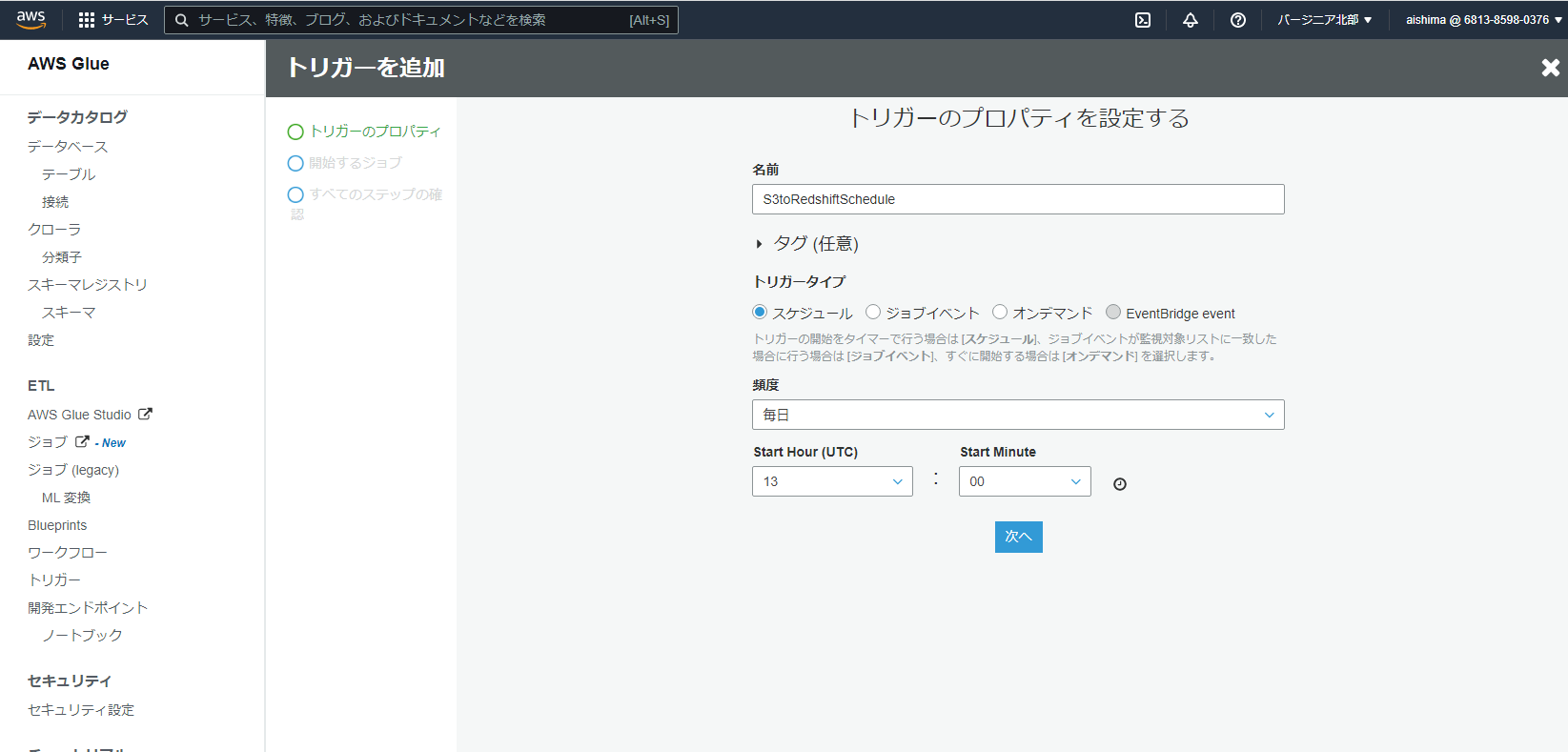
作成したジョブを開始するジョブに追加し、次へを選択します。
これで、S3のデータを定期的にRedshiftに転送するスケジュール設定が完了です!
Glue内での操作は一旦ここまでで終了です。手順の数は少なくないですが、UIのみで設定ができ、プログラミングスキルがなくてもできるのは大きいのではないでしょうか。
Redshift内でスケジュールクエリを使ってデータの整形を定期実行する
GlueによるS3→Redshiftへのデータ連携を設定することで、設定条件のうち
- データはS3内の同一のフォルダに毎日同時刻に格納される
- S3内のデータは前日の24時間分の履歴(前日の購買データやWebアクセスログのようなものを想定)
に関しては、無事、Redshiftに連携できました。後は、
- Redshiftには累計データを保管したい、またS3のデータをそのまま格納ではなくある程度整形して保存したい
↑を自動連携したい
を実現していきます。
方法としては、いくつかありGlueに慣れている方だとPyspark等が思いつくと思いますが、今回はGlueは簡単な設定のみを行い、残りの処理はRedshiftで行おうと思います。
テーブルの整形クエリを書きます。今回は単純なクエリにし、seller_stateの値がSPのもののみを抽出し、履歴として残しておくとします。出力結果は整形後のデータを保管するテーブルに格納するものとします。
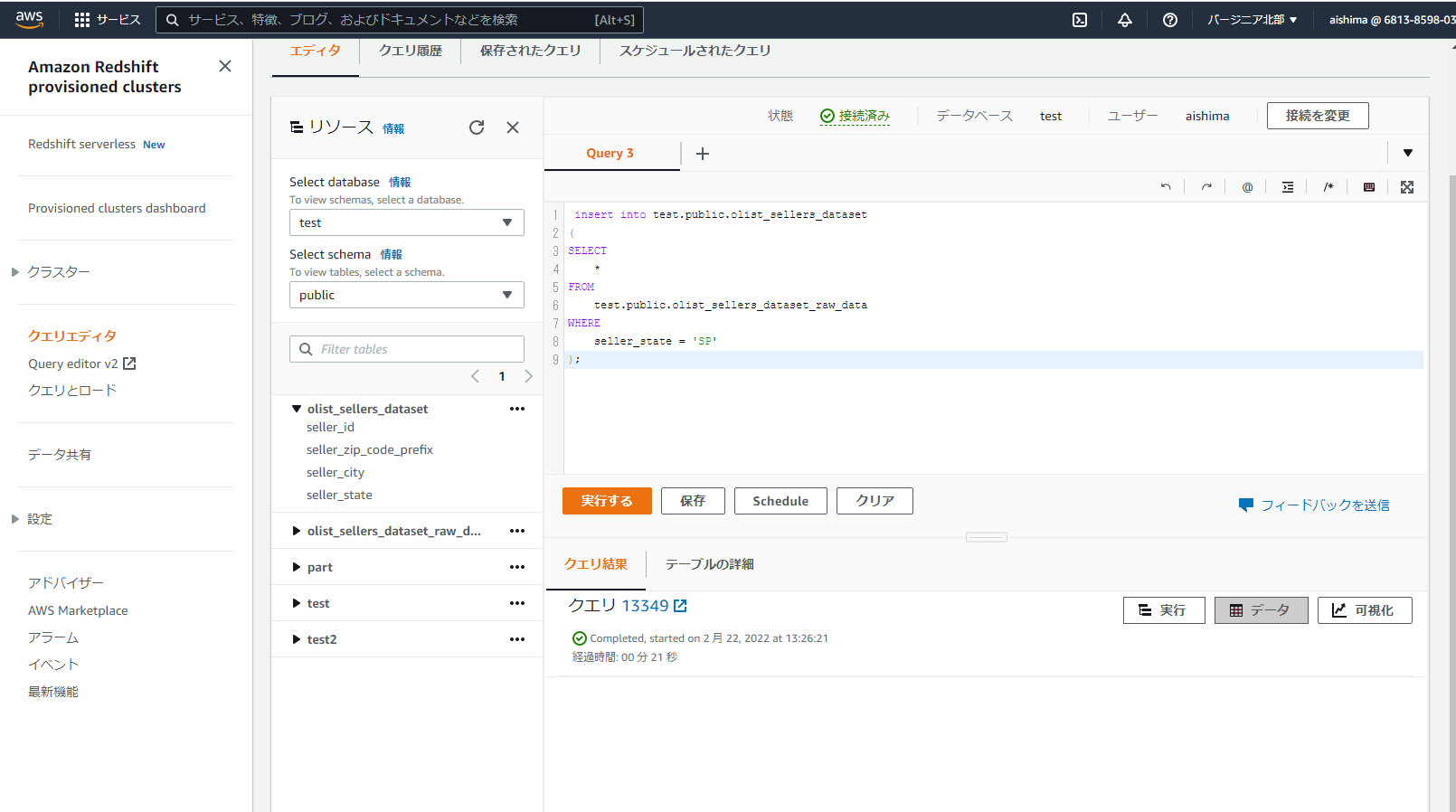
作成したクエリは任意の名称で保存しておきます。
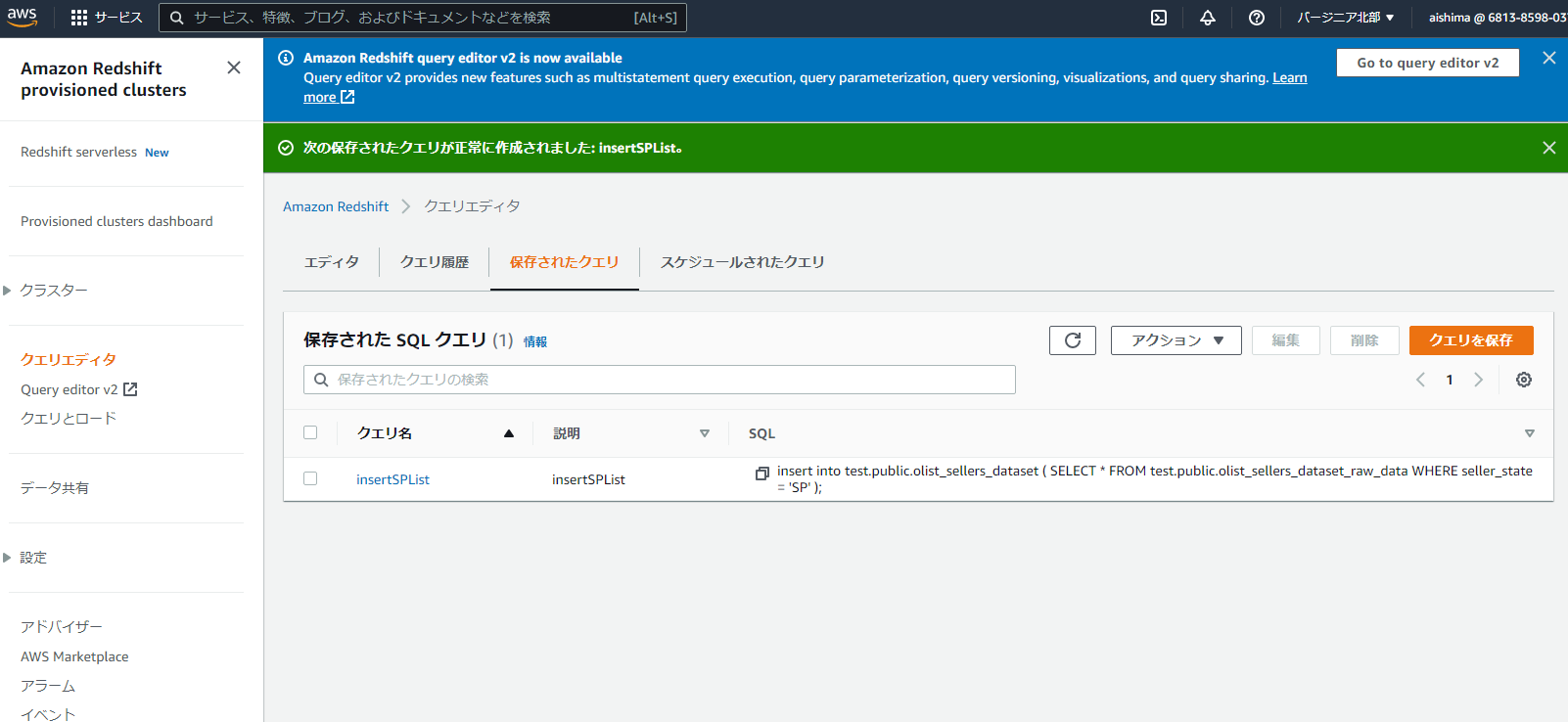
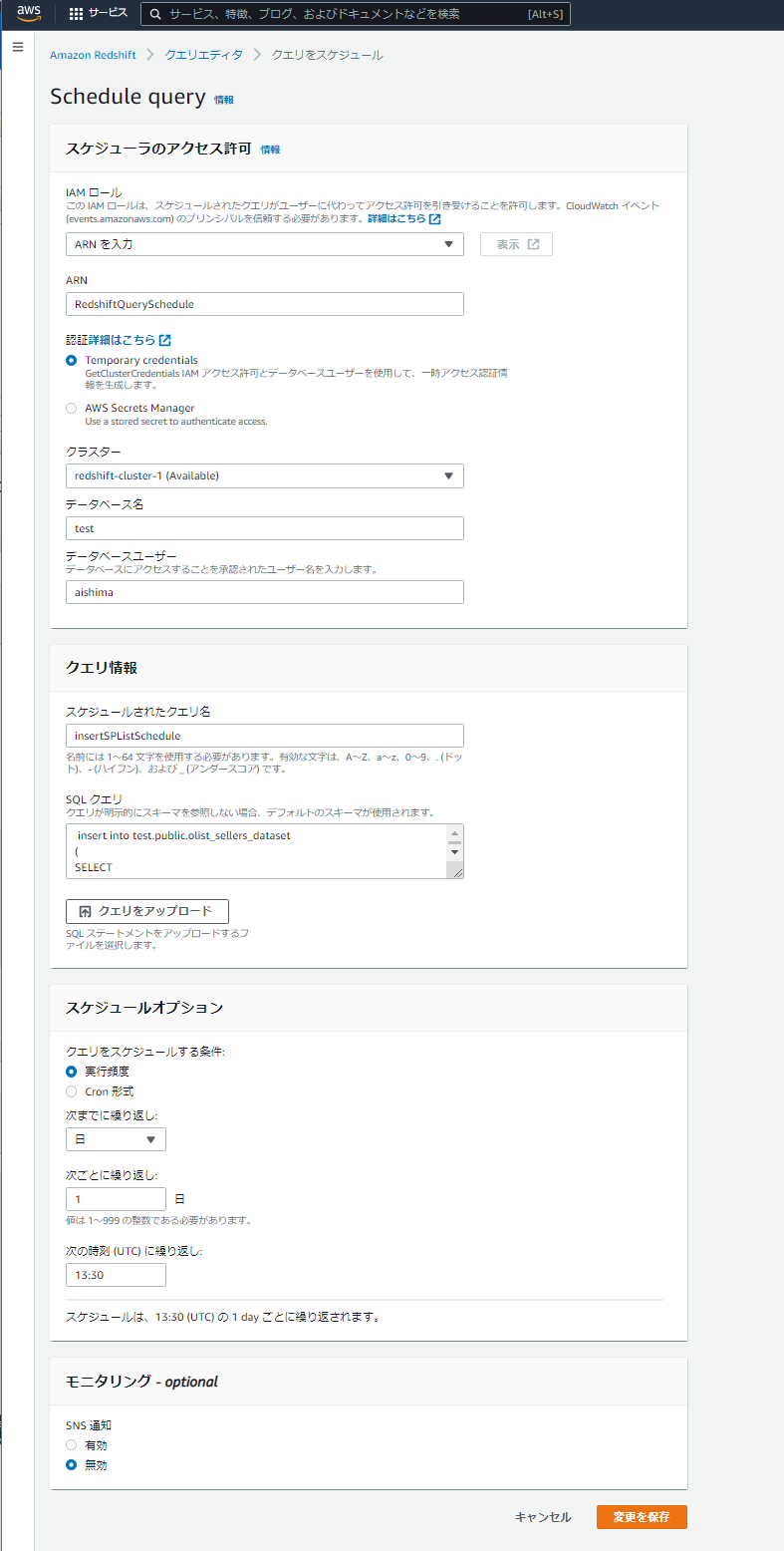
クエリスケジュールを実行する際に、ロールを準備しておく必要があります。今回は別途作成しておいたRedshiftQueryScheduleというロールを使用しています。作成に関しては以下のURLを参考に必要な権限をセットしました。
スケジュールオプションで、毎日13:30に実行するように設定しました。これで、
- S3→13:00にデータ転送→Redshift→13:30にデータ整形
の流れを実装できました!
まとめ
今回、S3のデータをRedshiftに自動連携するケースをGlueとRedshiftのスケジューリングを使って実装しました。
同じことを実現するには、他にも方法があるかと思いますが、自分の場合だと今回のやり方では以下の点から学習コストが高くないメリットがあると感じています。
- ほとんどUIベースで設計できる
- 使用言語がSQLに限定できる
- Redshift内で整形しているため
一方で、複雑なデータ整形が必要になる場合や、多くの種類のファイルの転送が必要になる場合だと、作業量が増えてくるといったデメリットも考えられます。
そういったパターンも踏まえて、PysparkやCloudformationでの実装も検討していきたいですね。