
社内版ChatGPT クローン 「GiFT」を開発しました
はじめまして。プロダクトエンジニアリング部の yonezawa です。
今回は私が昨年末に社内公開した 社内版ChatGPTについて下記目次の通りご紹介します。
目次
自己紹介
私は2022年4月に中途入社し、現在2年目のエンジニアです。前職は不動産営業をしていました。
根っからの文系ではありますが、 HTMLやCSS が大好きで、プログラミングには前々からとても興味があり、いつか仕事にできたらなと思っていました。
入社後1年目は当社のプロダクト「kreisel(クライゼル)」チームに配属されました。古くからのお客様がたくさんいらっしゃる大きなプロダクトであるため、安定運用が第一で、そのための日次業務に就いていました。あとはkreiselに関わらず当社プロダクトの運用定型業務を担うチームに属していました。
業務の中で自動化や一部機能改修のためのコードを書いたりはしていましたが、プロダクトの開発に設計段階から携わる経験はなく、「一からコード、書きたいなあ…」とはずっと思っていました。
以降は、ほぼひとりで勉強しながらChatGPTクローンのシステムを作ったよという話です。
社内版ChatGPT クローン 開発のきっかけ
OpenAI社のChatGPTの登場で巷での生成AI活用が始まるにつれ、当社でも社内でのAI活用を取り入れていく流れになりました。
そのためにまず最初の一歩として社員のためのChatGPTの利用環境を用意する必要がありました。
ChatGPTのエンタープライズ版を契約するよりもAPIを利用して構築したほうがぐっと料金も安くなるので、社内版ChatGPTを開発しよう、という上層部の判断があり、そこに私がアサインされました。
私がアサインされた理由は、前述の通り私が他方で「がっつりコードを書きたい」とわがままを言っていて、それを上司が汲み取ってくれたからです。
ちょうど社内版ChatGPTを開発したいという会社の意向とタイミングがマッチしました。やりたいことをやらせてくれる当社の風土にとても感謝しています。
GiFTの特徴
当社で社内版ChatGPTとして開発したGiFTの特徴は下記です。
- 社内の情報を投げてもOpenAIに学習されない
- 社内ドキュメントを読ませてそれを元に回答させることができる
- SAML認証
- 共有機能(※共有ユーザを指定できる)
- GPT-4が本家ChatGPTよりも安価で使える(API)
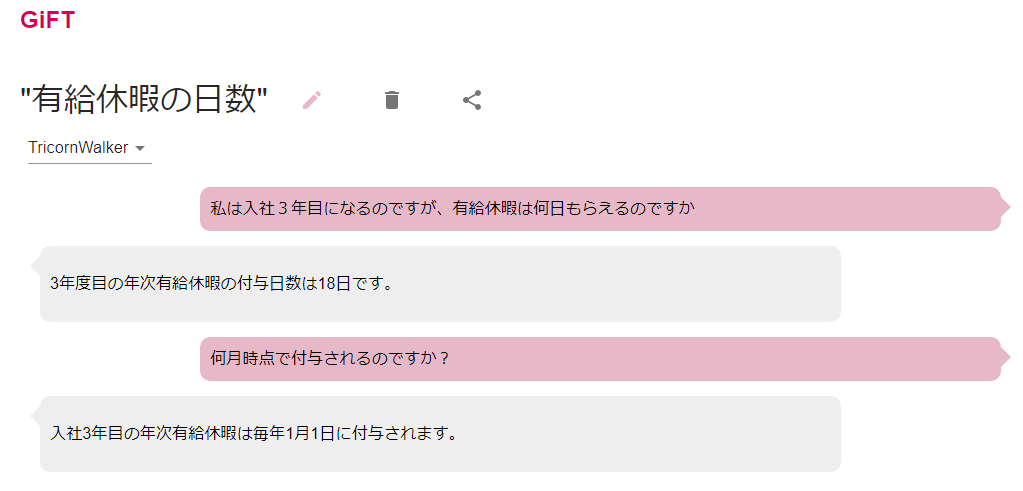
多くの企業でも社内版ChatGPTの導入が続々と進んでいると思います。
基本的には例に漏れずそれらと同じ特徴を持っていますが、SAML認証や共有ユーザを指定できる共有機能など、セキュアな仕組みも併せて構築しました。
技術
- 【フロントエンド】
- React (JavaScript)
- UIフレームワーク:Material-UI
- バックエンドとの連携:axiosによるAPI通信
- 【バックエンド】
- Django (Python):OpenAIとのAPI通信で回答のデータを取得
- LLMライブラリ(LangChain):生成AI言語モデルの機能拡張を効率的に実装するためのライブラリ
- 【Webサーバ】
- nginx
- 【開発環境】
- Docker
- 【データベース】
- PostgreSQL
- 過去の問い合わせ内容、ログインユーザの情報などを格納
- PostgreSQL
だいたい設計~リリースまで5か月ほどでした。実装期間は2か月ほどになります。
作った感想
設計やLLMライブラリの利用検証などの準備に時間がかかったことで、実際の実装期間が短くなり最後らへんはてんやわんやでしたが、何とか社内に公開することができました。
ReactもDjango も初めて扱ったので、キャッチアップも並行して行うことが大変でした。
とはいえ、OpenAIのAPI を利用してデータを投げ、返ってきたものをどう表示するか、というところが実装の要だったので、逆に言うと内部での生成AI系の処理はLLMライブラリ(Langchain)が全ていい感じにやってくれたので助かりました。
ChatGPTクローンに直接関係はないですが、SAML認証周りについては結構実装の時間を費やしたので記載しておきます。
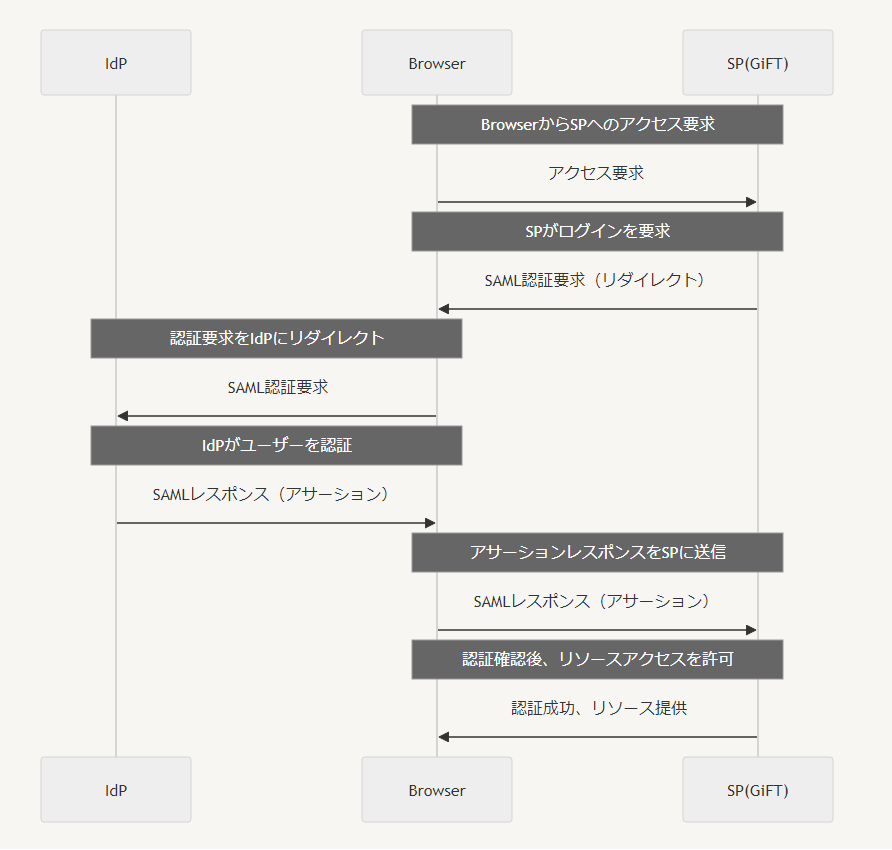
SAML認証を使うと、一度のログインで様々なサービスへのアクセスを提供するシングルサインオンが実現できます。認証情報をIdP側で一括管理することでセキュリティを高めつつ、運用の効率化を図れます。
当社の勤怠管理などの様々なツールですでに運用されているIdPの認証フローを利用することでメールアドレスおよびパスワードでのログイン処理をスキップすることができました。

実装前には認証のフロー図を書くところから始め、ウェブサービスのSAML認証に共通する見識を深めました。
SAML認証には下記のパッケージを利用しました。
https://github.com/SAML-Toolkits/python3-saml
※ demo-djangoディレクトリにサンプルコードがあります。
IdP側で認証が成功したらメールアドレスを返すようにして、そのメールアドレスを元にDBのユーザ情報と突き合わせて一致したらログイン状態にする、という流れです。
社内ドキュメントを読ませるには
ここから、GiFTの実装の中で肝となった「社内ドキュメントを元に回答させる」処理について、下記の二つに分けて説明してきます。
- A.社内ドキュメントを事前に保存しておく
- B.会話履歴を保持しつつ、社内ドキュメントを元に回答を取得する
処理の概要
まずはそれぞれの処理の概要について説明していきます。
A.社内ドキュメントを事前に保存しておく
生成AIの回答に社内ドキュメントを反映させるためにはドキュメントのデータをあらかじめ保存しておく必要があります。
保存する際はドキュメントを塊に分け、ベクトル化して、ベクトルDBに保存します。取り出すときは、ベクトルデータを索引(インデックス)のように使い、関連性の高いドキュメントを塊単位で取り出します。
ベクトル検索というのは、関連性の高い類似した情報を引き出すための手法です。
例えば「有休」というキーワードで検索したら、ドキュメントの中の「有給休暇について」の情報が返ってきます。
もっとわかりやすく知りたい方はこの記事を参考にしてみてください。
https://note.com/higty/n/n1c7889acefd4
保存までの流れは下記です。

① 社内ドキュメントを読ませる
(例)休暇について記載されたドキュメントのデータ
「有給休暇は、入社1年目は〇日、2年目は〇日・・・結婚休暇は、〇日付与される。・・・」
Notion, Confluence, PDF など
② ①を、文脈を保持した一定の塊に分割する
(例)「有給休暇は、入社1年目は〇日、2年目は〇日・・・」、「結婚休暇は、〇日付与される。」、・・・
③ ②を、ベクトル化する
④ ③を、ベクトルDBに保存する
B.会話履歴を保持しつつ、社内ドキュメントを元に回答を取得する
A. で保存したドキュメントを元に会話履歴を考慮した回答を取得する処理です。

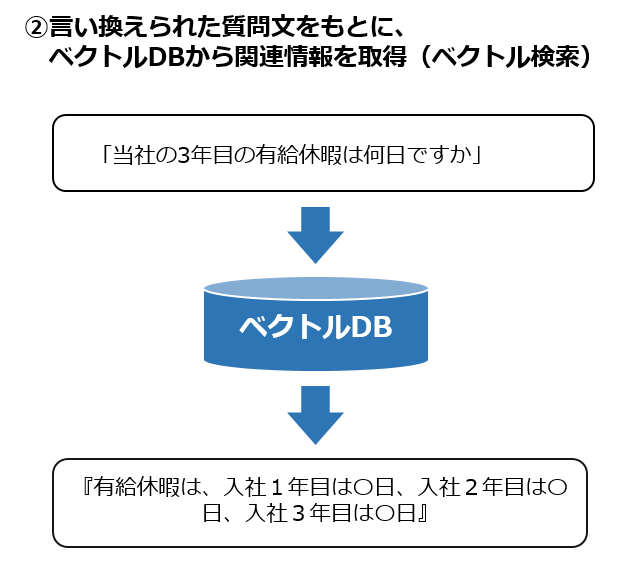
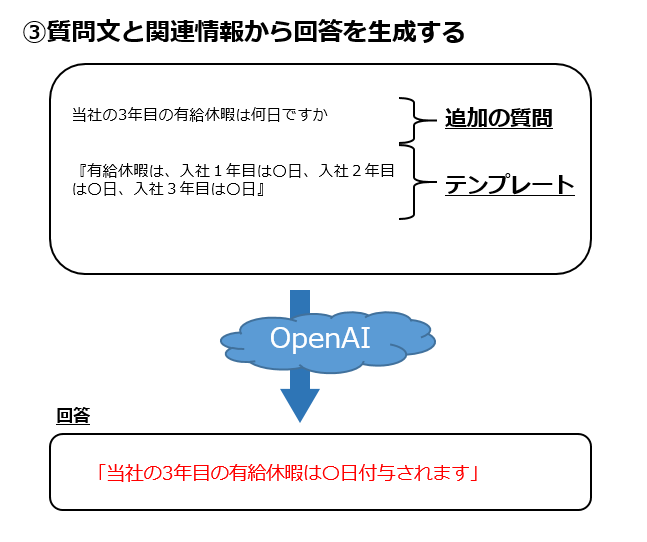
①質問を投げると、会話履歴をもとに質問文の言いかえ(補足)を行う
②言い換えられた質問文をもとにベクトルDBから回答になりそうな情報を取得(ベクトル検索)する
③ベクトルDBから取得した答えになりそうな情報と、言い換えられた質問文を元に回答を生成する
※A.社内ドキュメントを事前に保存しておく でドキュメントをベクトルDBに保存しておく際、文脈を保持しつつ小さな塊に分割しておけば、②でAPIを実行する際のトークン数(≒文字数)が少なくなり、API利用料金の節約ができます。
処理の詳細
A.社内ドキュメントを事前に保存しておく
A図①『ドキュメントを読ませる』処理については、Langchain の Document loaders というクラスを使います。
Document loadersには、テキストをそのまま取得するTextLoaderや、Notionの内容を取得する NotionDBLoader、PDFを取得するPDFLoaderなど用途に応じて様々な種類があります。
A図②『読ませたドキュメントを文脈を保持した一定の塊に分割する』処理については、塊に分割するために TextSplitterというLangchainのクラスを利用します。 TextSplitterにはいろいろ種類がありますが、私は下記の CharacterTextSplitterをつかいました。
CharacterTextSplitter : https://python.langchain.com/docs/modules/data_connection/document_transformers/
separatorを指定するとそこで区切られます。たとえば “\n\n” と指定すれば、改行が二つきたタイミングで区切られます。
A図③・④『ベクトル化して、ベクトルDBに保存する』では、TextSplitterで区切った塊をベクトル化して、ベクトルDBに保存します。ベクトルDBはChromaDBを使用しました。ChromaDBに保存する際は、データを永続化するために、PersistentClientクラスを使いました。
具体的なソースコードは下記ですので、よければ参考にしてください。
(おまけ)実装時に試行錯誤した点
今回ドキュメントを読ませる際は、当社社内ドキュメントはNotionにまとめられているため、
それらのNotionのページをマークダウン形式で一度すべてエクスポートしてから、それらのファイルをTextLoader で取得し、separtorには”#” を指定するという手法を取りました(TextLoaderではなく MarkdownLoader を使ってもいいかもしれません(未検証))。
なお、はじめはNotion用のNotionDBLoaderをつかおうと試みたのですが、実行してみると、見出しも本文も区別なく文字列として取得してしまい、separatorをどこに指定するか悩んでしまったので、マークダウン形式のファイルを扱いTextLoaderで取得することにしました。
私が読ませた社内のドキュメントは、そもそも学習データとして読ませるという前提があるものではないので、書く人によって見出しのつけ方だったり改行のタイミングが異なったりしていました。情報をツリー形式でそのまま箇条書きする人もいたり。
そんなこんなで体裁が統一されておらず区切り方に苦労したので、結局、既存のドキュメントを無理やり読ませるよりも、ちゃんと保存用に体裁を整えた「読ませる用の文書」を用意したほうが精度は上がるなと思いました。FAQのリストを用意しておいてそれを読ませておくなど。
ちなみに後日、TextSplitterの種類に、SpacyTextSplitterというのがあることを知りました。
SpacyTextSplitterを使うと、separatorを指定する必要がなく、大体日本語の文脈でよしなに区切ってくれるようです。
※ spaCyとはPythonの自然言語処理ライブラリ
※ Spacyのカスタム: https://zenn.dev/toohsk/articles/07bb7702b23b8c
これだと体裁整ってなくてもある程度大丈夫かもしれません。
B.会話履歴を保持しつつ、社内ドキュメントを元に回答を取得する
会話履歴を保持しつつ、社内ドキュメントを元に回答させるため、Langchainの「ConversationalRetrivalChain」という機能を使います。
B図①「質問を投げると、会話履歴をもとに質問文の言いかえ(補足)を行う」処理において、会話履歴の保持にはLangchainのmemory機能の中の、ConversationBufferMemory()を利用しました。こちらは今までの会話履歴をすべて保持します。
Messageモデルにはquery(質問文)とresult(回答文)のカラムを持つデータが入っているので、それを memoryに格納するという処理を取っています。
下記のmemory機能も検討しました。
- ConversationBufferWindowMemory()
- 引数で指定した件数だけ直近の会話履歴を保持する。
- ConversationSummaryMemory()
- いままでの会話履歴の要約だけ保持したい場合。トークン数を抑えられる(=料金が安く済む)。
B図②ではChromaDBを呼び出してデータベースを読込みし、Langchainのas_retrieverメソッドを使って関連性の高い情報を抜き出します。
③ではConversationalRetrievalChainで、①で言い換えた質問と、②で得た関連性の高い情報をOpenAIに渡し、最終的な回答を生成します。
具体的には下記ソースコードの通りです。
社内での利用シーン・もらった感想
社内リリース後、生成AIにもともと興味を持っていた人はもちろんですが、多くの人が興味をもって使ってくれました。
社内ドキュメントを元に回答させる方についてはドキュメントの読ませ方も相まってまだまずまずの出来ですが、社内ドキュメントを読ませていない方は、GPT-4を導入しているので、本家と違って、GPT-4を気軽に使えることが社員にとってメリットのようです。
またコードを書くときの参考にしたり、メールのひな型を作ってもらったり、表を成形してもらったり、利用シーンとしては本家ChatGPTから特別逸脱することはありませんが、やはり社内の情報をマスクしないで問い合わせを投げられるというのは使い勝手が良いみたいです。
今後の展望
やはり当社独自の、というところで、社内ドキュメントを元にした回答の精度の向上を目指したいと思います。
特定の強みを持つBotを作って(本家GPTsのような)それを元に回答させる、ような機能を作りたいと試みています。Botを利用者側(社員側)で作成・カスタムできるとさらに便利ですね。
キャラクター性を持ったBotを増やして、社内で便利に使われ愛されるプロダクトになったら嬉しいです。
GiFT社内リリースによるChatGPTの利用促進を足掛かりに、当社のお客様向けのプロダクトに関しても、AI関連の機能開発のアイデア出しが活発化したり、既存業務の効率化が促進することを期待しています。