
7日間かけてStable Diffusion WebUIによる人物画像生成の学習に取り組んでみた
データマーケティングGに所属しているaishimaです。
普段は Tableau、Treasure Data、Salesforce を使用してデータ分析周りの仕事をしてます。
今回は普段の業務とは関わりのないところで、個人的に興味があり学習した内容について記事にしました。
AI を使った人物画像生成のスキルアップの様子をお伝えできれば幸いです。
Stable Diffusion WebUI を動かし始める
YouTubeを見ていると、たまたまAIによる画像生成の設定手順について紹介してあった動画を見つけました。Stable Diffusion WebUIに関するもので、Google Colaboratoryを起動して、YouTubeの概要欄に貼ってあるソースコードを貼り付けると、WebUIが起動し画像生成を始めることができるものでした。
前から、知ってはいたものの中々実際に動かす機会がなかったのですが、なんとなく気になり時間もあったので自宅のPCで動画の手順に沿って設定していきました。動画で紹介されたのは、あくまで設定手順のみで自分が生成したい画像を作成する方法やテクニックに関しては、後ほど別途調べていきました。
動画を見つけて初日は画像を生成するために、プロンプト(AIに生成したい画像を認識させる呪文のようなもの)をいじったりしているだけでしたが、少しずついい感じの画像が生成されるようになっていき、だんだん楽しくなってきました。最近仕事以外の時間もあるし、少し勉強してみようと思ったのですが、結果としてかなりハマってしまいかなりの時間をキャッチアップに費やしましたw。おかげさまでStable Diffusion WebUIのスキルもそれなりについたように感じています。現時点で足りない知識をキャッチアップしていくだけでもボリューム感満載でしたが、さらに学習中にいくつも最新の機能がリリースされていき、リアルタイムでそれらの機能を試したりもしました。こういった最新の情報が次から次へと更新されるジャンルを学習していくことがあまりなく新鮮だったので、その辺りもどういう風にキャッチアップしていったかみたいなのも紹介できたらと思います。
取り組み始めて1~2日目
取り組み始めて初日の段階で、UI起動までは自力でできるようになっており、ある程度のプロンプトでの実行も試せるようになりました。ただ、紹介のあったYouTubeの概要欄に貼ってあるプロンプトだとなかなか動画のような綺麗な画像にならず、この情報だけでは限界があると感じ、記事や他の動画でプロンプトを調べることにしました。この時点のキャッチアップ段階では、目の大きさや、カメラアングル、表情などを指定するだけで、ある程度満足が行くそれなりのクオリティのものができ(今振り返るとそうでもなく、人物ぽいがAIであるとひと目見ただけでわかるレベル感)、毎回実行するたびに違った画像ができるのが楽しくなり、ひたすらプロンプトのパラメータを微調整しながら大量の画像を生成していました。
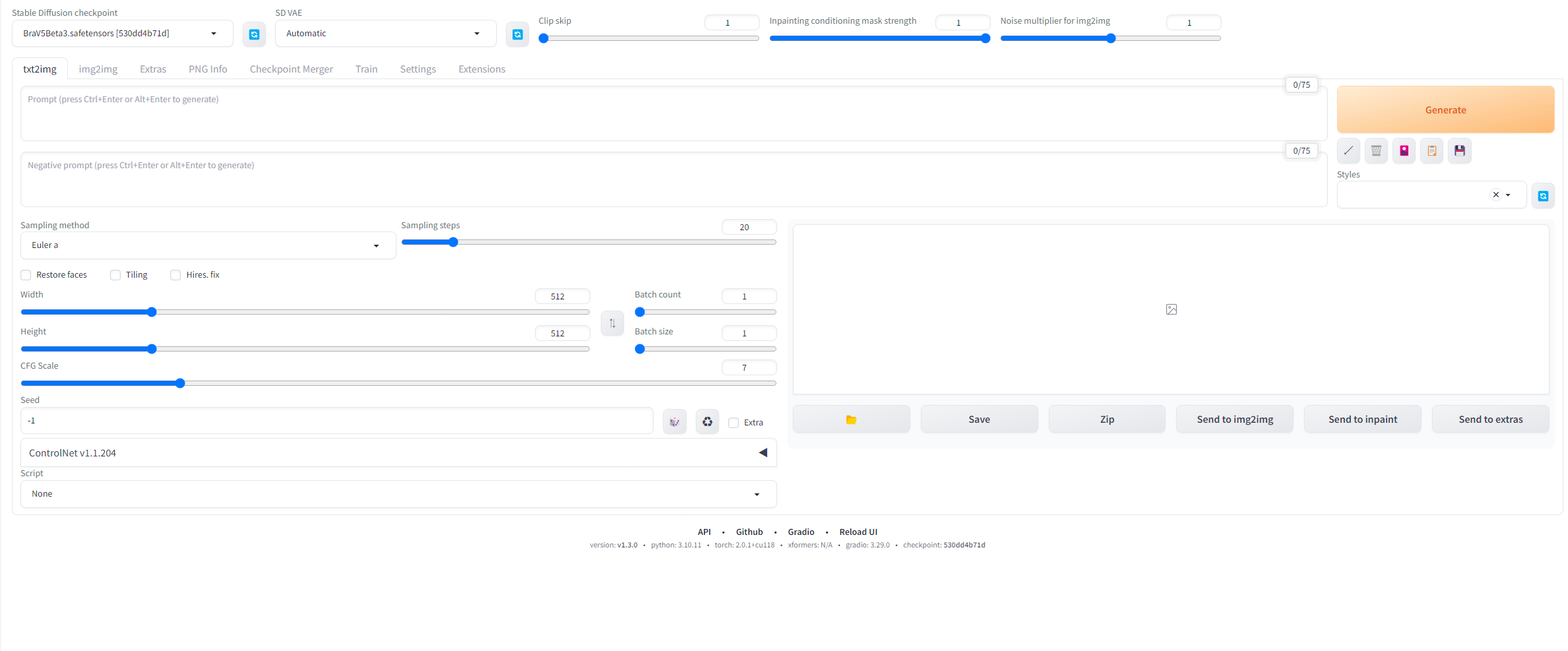
Stable Diffusion WebUIで使用するGoogle Colaboratoryですが、おそらく数十枚程度までなら無料枠で生成可能です。ただ自分の場合あっという間に使い切ってしまい有料枠を購入しました。ただあまり考えずに、使い続けてしまい、数日で利用枠が消化されてしまいました…。調べたところ、接続するGPUのタイプによってかなり消費速度が変わってくる、かつ特に指定しないと勝手に自動で最速のプランに設定されることもあるようで、一度はランタイムからプランを逐一変更するようにしました。ただ、やはりプランが高いほうが画像一枚あたりの生成速度はかなり早くなるので、ある程度慣れてくるとプランに関しては最速のプランの方がいいのかなと思い直しました。
ここで、Stable Diffusion WebUIで何回か作業するうちに、自分が参考にした動画の起動方法だと、毎回実行するたびに1から実行する必要があり、Google Colaboratory上にファイルを残せない仕様になっていました。最初はあまり気にならなかったのですが、毎回UI上で作成したプロンプトが消えてしまい、その度に、いい感じの画像ができたとしても自分の方でどこかに記録するのを忘れていて、前回の分を再現するのに時間がかかっていたりしました。
そういえば自分もトライコーンで仕事をする際に、自分が作成したプログラムや作業録を残しているなぁと思い、(トライコーンでは Confluence を使用して社内で社員の知見を共有する文化があります)せっかくだし、きちんと作業録を残して学習することにしました。今回は個人の趣味で行っていることなので、今まであまり使ったことがなかったのですがNotionを使うことにしました。起動設定や、作成に使用したプロンプトを毎回まとめたり、参考したURLや、プロンプトを試してみて実際に効果があったのかをまとめたりするようにしました。プライベートの学習だったのですが、Notionで記録を残すようになってから作業のやり直しがなくなり、キャッチアップの速度もかなり上がった気がします。振り返ると早めにやっておいてよかったな…、と思いました。
取り組み始めて3~7日目
取り組み始めて3日目の時点で、YouTube等で他の人が作成した画像を見たりしていて、このままプロンプトを調整していってもなにか超えられないクォリティの壁があるな…、と感じていました。YouTubeで色々調べて、LoRaといった追加学習モデルがあることを知り、いくつか試しそれなりにきれいなものもできましたがまだ何かが違うなぁと思いながら、試行錯誤していました。
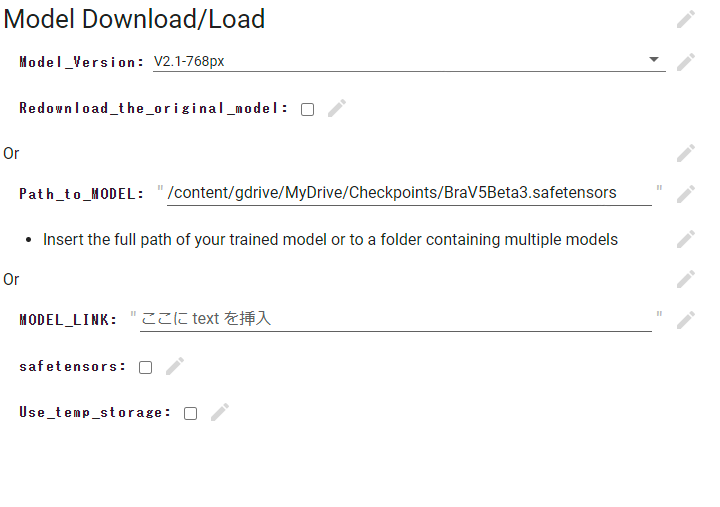
画像のクォリティが一気に上がる最初の転機になったのは、3日目の寝る前に見たYouTubeでBRA V4に付いて紹介してあった動画を見つけたことです。動画で紹介されていた画像がかなり、実写に近くぱっと見だったらほとんど見分けがつかないレベルでした。「見つけた!」と頭の中で思ったのですが、さすがに疲れていたのでそのまま寝ることにしました。起きてからは、すぐにYouTubeを確認し、BRA V4の設定を行いました(取り組み始めて4日目)。また、この時点で最初に見た動画のStable Diffusion WebUIの起動方法だとモデルの適用ができなかったので、別の方法での起動方法について説明のある動画を調べて、見つけた動画の手順に従いました。なお最初に見た動画はかなり参考になったのですが、毎回実行するたびに1から実行する必要があり、Google Colaboratory上にファイルを残せないこともあり、これ以上の画像の向上が望めないこともあり、おさらばすることにしました。BRA V4の設定に関して紹介している動画の概要欄に貼ってあるプロンプトをそのまま載せてみて、画像を生成してみたところ、ある程度うまく行ったので後はパラメータ調整を行いリアルな人物画像になる値を探していました。
一方で、それなりに実物っぽくはなるのですが、いまいち昨日の寝る前に見た衝撃のような本物感を作ることはできていませんでした。これは、このままプロンプトを調整していっても中々到達できなそうな感覚でした。とはいえ、違和感を感じつつも遅くまで色々調べていたので就寝につきました。何か見落としてないかと思い、寝る前にYouTubeを見て、昨日見たYouTuberの動画一覧を見ました。すると、自分が今日BRA V4の設定の際に参考にした動画の2つ後にアップされた動画がBRA V5について紹介する動画でした!(おそらく昨日自分が見たのはこの動画で、今日の朝見間違えてしまったようで。。)動画をざっと見ると、昨日寝る前に見た動画はコチラだった・・と再認識しました。BRA V4も十分すごいモデルですがBRA V5になると更に実在の人物と見分けがつかないクォリティでした。「これだ!」と頭の中で思ったのですが、さすがに疲れていたのでそのまま寝ることにしました。
次の日に起きてからは、すぐにYouTubeを確認し、BRA V5の設定方法に関する動画を確認しながら設定を進めていきました(取り組み始めて5日目)。ただ、BRA V5はまだ試用版しかないらしく、月額料金が必要とのことでした。ここまできて、好奇心を抑えることができず購入することにしました。BRA V5の設定に関して紹介している動画の概要欄に貼ってあるプロンプトをそのまま載せてみて、画像を生成してみたところ、ある程度うまく行きました。後はパラメータ調整を行いリアルな人物画像になる値を探していました。
なお、BRA V5に関しては商用利用も可能なモデルになっているようです。
https://photoshopbook.com/2023/05/21/stable-diffusion-models/
ここまでくると、自分の方でもかなり実写に近い人物画像を生成することができるようになりました。今までは実物の近さのみにフォーカスを当てていたのですが、段々他にもできることを増やしてみたくなりました。なのでこの日は様々なプロンプトを試してどのようなことができるのかを調べていました。例えば、背景にどういったものを設定できるか、服装や髪型の指定、服装や髪型の色の指定、どういった装飾品を身に着けれるか、表情にはどういった指定ができるか、等々。
慣れてくると、様々な背景でほぼ写真のようなものを作れるようになるのですが、気になるところも出てきて、特に姿勢に関してですが、何も指定しないとただ立っているだけだったり、座っているだけだったりと変化に乏しいものが作られていきます。しかしながら、プロンプトで細かい指定をしてみても逆に画像が壊れてしまったりもします。指定したポーズで描写するのは難しいのかなと思いながら、色々試していると遅い時間になったので就寝につきました。寝る前にYouTubeを見ていると、(ここ数日の視聴履歴からかホーム画面には最近アップされたStable Diffusion WebUIに関する動画ばかり!)Stable Diffusionで新機能がでたとの動画がありました。アップロードも数時間前で気になり見てみました。すると、ControlNetのopenposeを使った機能で、なんと特定の姿勢を取った画像をUIにアップロードすると、その姿勢を読み込んで、同じ姿勢の画像を生成してくれるという機能がリリースされたという内容でした。かなりタイムリーに課題に感じていた内容だったので、早速試したいと思ったのですが、さすがに疲れていたのでそのまま寝ることにしました。
次の日に起きてからは、すぐに就寝前に見つけたYouTubeを確認し、設定方法について学習しました(取り組み始めて6日目)。Webサイトからいくつかサンプルでポーズを取っている画像をダウンロードし、どのように画像が生成されるのか試してみました。結論いくつかの画像では想定した姿勢を取ることができましたが、画像が完全に壊れてしまうものも多く、ある程度元となる画像を厳選しなきゃいけないのかなというところでした。ただ画像を準備するのにもある程度時間もかかるので、ポーズにそこまでこだわりがないのであれば、大量に画像を生成してその中から気に入ったものをいくつか採用するとかでもいいのかなと思いました。
新機能の検証をひと通り終えてからは、次の日にかけても、飽きることがなく色々検証していました(取り組み始めて7日目)。
余談なのですが、上記のように一気に学習してから、そう期間が立たないうちに新しい動画がアップロードされ、確認したところ「BRA V5がリリースされました」というものでした…。もう少し我慢していれば無料で利用できました…。ただ、あの時点でいつ公開されるのかわからないまま待てはしなかったので、まぁしょうがないかと切り替えることにしました。
まとめ
約1週間一気にStable Diffusion WebUIを使った人物画像生成のスキルアップに取り組みましたが、技術的な知見の取得もそうですが、他にも色々学ぶこともありました。まず、今回自分でも初めてYouTubeを中心に情報のキャッチアップを行いましたが、個人的にはなかなか良かったのかなと思いました。丁寧に説明してある動画がたくさんあり、また最新の情報が出たら次の日にアップロードしてくれているクリエイターもいたりと、初心者でほとんど知識がない状態でもあまり苦労することなく習得することができました。また、YouTubeの場合、学習用に一定数の動画を見ているとおすすめで対象の動画をどんどん上位に表示してくれるようになります。このおかげで、自分が調べる前に気になっていたことが上に来た動画を見るだけで解決することがあったりしたので、かなり助かりました。勝手に知りたいであろう情報をおすすめしてくれるのは、通常の検索で記事を探すのとは違う、YouTubeの強みかなと思いました。学習するジャンルによってはYouTubeを取り入れてみるのも悪くないのかなと思いました。
また、一気に学習していた期間の後半(4日目以降)ではBRA V5のモデルを適応して、ある程度のパラメータの基本的な設定が実装できてからは、背景等を変化させたときの細かいパラメータ調整が主な作業になってきました。この辺りは、本当に細かい調整が必要で、少しあるパラメータの重さをいじるだけでもきれいな画像が生成される確率が変わってきます。ただ、今回は逐一前回使用したパラメータの数値をNotionで記録しておくようにしたので、効率よく最適だと思われるパラメータの調整ができていたと思います(ここは普段の仕事の取り組み方が役に立ちました)。
アウトプット
参考までに、今回作成した人物画像の一部を時系列で載せようと思います。(変化が結構分かるのではないかと思います)
取り組み始めて1日目

取り組み始めて4日目

取り組み始めて7日目

これからやりたいこと
記事を執筆した6月時点でも Stable Diffusion WebUIの学習は未だに飽きることなく続けられてます(一気に取り組んだ期間に比べると1日あたりの時間は減りましたが)。最近も「指定した同じ顔で何枚も画像を生成できる(通常だと生成するたびに違う人物の画像になる)」機能がリリースされたりと(ControlNetのReference Only)、しばらく目が話せなそうな分野で追いかけていこうと思います。